 田帅康学习笔记
田帅康学习笔记记录一种校验方式-crc16(python+C语言)
最近在写boot升级代码时,需要上位机发送固件包到下位机,因为固件包太大,因此需要分包发送,分包发送涉及到校验问题,特意对crc16校验方法进行记录计算方法预置1个16位的寄存器为十六进制FFFF(即全为1,我称为种子);称此寄存器为CRC寄存器;把第一个8位二进制数据 (既通讯信息帧的第一个字节)与16位的CRC寄存器的低8位相异或,把结果放于CRC寄存器;把CRC寄存器的内容右移一 位(朝低位
最近在写boot升级代码时,需要上位机发送固件包到下位机,因为固件包太大,因此需要分包发送,分包发送涉及到校验问题,特意对crc16校验方法进行记录计算方法预置1个16位的寄存器为十六进制FFFF(即全为1,我称为种子);称此寄存器为CRC寄存器;把第一个8位二进制数据 (既通讯信息帧的第一个字节)与16位的CRC寄存器的低8位相异或,把结果放于CRC寄存器;把CRC寄存器的内容右移一 位(朝低位
如果不将模型部署在边缘设备上加以使用,那我们的模型将毫无意义怎样在STM32上运行神经网络以及进行推理STM32最常用使用C语言开发,也有少许用micropython或者是lua开发,但是这些都不在主流范围内,再者说在STM32上使用torch等网络推理框架也是相当不现实。因此我们需要在C环境下使用神经网络推理框架,经过我的寻找,在github上找到了这几种使用C语言实现的推理架构:sipeed/

搭建一个怎样的模型KWS模型结构属于比较简单的模型结构,但是为了少走弯路,我计划使用现成的结构,我从这个演示视频参考而来:点击我跳转,这个KWS项目运行在AT32F403上,其网络模型结构为一个64个特征的普通卷积层,然后重复四次的DS-CNN卷积,在每次卷积后都进行一次relu,最后进行一次池化,用来减少全连接层的参数。模型部分代码如下:class Net(torch.nn.Module):

为什么需要样本神经网络模型的训练本质上是根据结果寻找最优解的过程,在这个过程中我们需要输入大量的样本以及正确的答案,帮助网络结构内部矫正自己的参数。样本如何获取speech_commands_v0.01下载地址,这里整理了数种常用的语音指令供我们使用,每种语音指令下大约有2300条语音数据,包括多种音色,不同背景噪声,具有普遍性。为什么要筛选数据后面我用来训练的数据是16KHZ采样率,时间长度为1
前景提要公司有一个新产品,产品定义上有一个很愚蠢的交互设计,耳机中有人打电话过来后,会有提示音播放是否接听,此时用户想要接听,随便说什么话都可以接通(甚至噪音都可以),如果不想接通就闭嘴,因此我来了兴趣,能否在单片机上运行简单的语音关键词识别简述keyword spotting什么是kws(keyword spotting),翻译过来就是关键词检测,例如小米音响、天猫精灵音响上都有小爱同学、天猫精

入门神经网络三C环境部署为什么要部署到C环境上面两篇文章中,我们详细讲解了采集样本与样本训练,生成了一个模型文件,经过测试我们的模型成功率在90%以上,但是我们想将这个模型利用起来,实时检测我们的运动姿态,在ESP32上运行torch显然是不现实的。因此我们将参数保存下来,用C语言复现一遍,在esp32上运算这样才有实际使用价值。网络结构中的数据变化我们的第一层网络结构为5个卷积核的卷积层(包含r
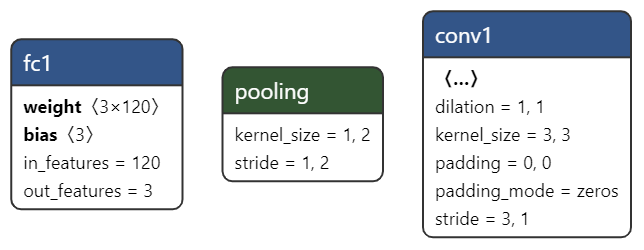
入门神经网络二网络搭建使用哪种深度学习框架目前主流的神经网络框架有tensorflow、kears,国产的有百度的PaddlePaddle,但是我是从yolov5入坑的,yolov5官方代码使用的是pytorch框架,所以我使用torch,而且torch框架上手很简单,资源较多坑较少。建立一个怎样的网络结构网络层网络层很简单,只有一个卷积层和一个全连接层,一个卷积层包括卷积、激活、下采样。我是用5
入门神经网络一样本采集在本科的时候对神经网络颇有兴趣,感觉很神秘,特别是当时的yolov5目标检测算法,让我感觉特别震撼,计算机在图像识别上已经超过了人眼。但是这么长时间以来一直停留在跑demo的阶段,没有静下心来学习,为此我计划搭建一个属于自己的神经网络作为入门标志,这是第一章,主要讲了说明采集样本的过程。建立一个怎样的网络我计划建立的网络结构,输入参数为陀螺仪三轴传感器的数据,输出内容为可能进
最近项目上需要混音算法,上网查阅了四种常用的混音算法,用python运行来做测试,测试完成的语音数据放在结尾可以下载混音算法一:加权平均这种方法很简单,直接将两个PCM样本相加,为了防止溢出再除以二,但是这种方式会导致声音细节丢失声音会变小,并且混入通道数越多,声音衰减越严重,毕竟原始音频直接右移了八位,实际测试下来也是如此,实现方法为:for i in range(0,sample_nums):
Numpy简单应用创建一个一维数组a = np.array([0, 1, 2, 3, 4]) b = np.array((0, 1, 2, 3, 4)) c = np.arange(5) d = np.linspace(0, 2*np.pi, 5) print(a) >>>[0 1 2 3 4] print(b) >>>[0 1 2 3 4] print(