 田帅康学习笔记
田帅康学习笔记入门神经网络-搭建自己的网络结构之C环境部署(三)

入门神经网络三C环境部署为什么要部署到C环境上面两篇文章中,我们详细讲解了采集样本与样本训练,生成了一个模型文件,经过测试我们的模型成功率在90%以上,但是我们想将这个模型利用起来,实时检测我们的运动姿态,在ESP32上运行torch显然是不现实的。因此我们将参数保存下来,用C语言复现一遍,在esp32上运算这样才有实际使用价值。网络结构中的数据变化我们的第一层网络结构为5个卷积核的卷积层(包含r
入门神经网络三C环境部署为什么要部署到C环境上面两篇文章中,我们详细讲解了采集样本与样本训练,生成了一个模型文件,经过测试我们的模型成功率在90%以上,但是我们想将这个模型利用起来,实时检测我们的运动姿态,在ESP32上运行torch显然是不现实的。因此我们将参数保存下来,用C语言复现一遍,在esp32上运算这样才有实际使用价值。网络结构中的数据变化我们的第一层网络结构为5个卷积核的卷积层(包含r
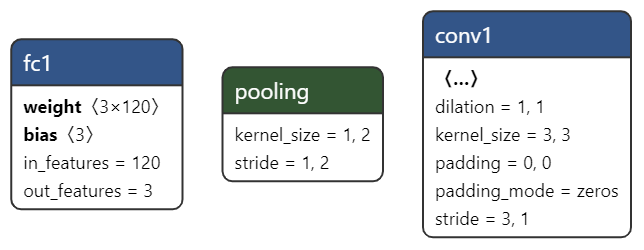
入门神经网络二网络搭建使用哪种深度学习框架目前主流的神经网络框架有tensorflow、kears,国产的有百度的PaddlePaddle,但是我是从yolov5入坑的,yolov5官方代码使用的是pytorch框架,所以我使用torch,而且torch框架上手很简单,资源较多坑较少。建立一个怎样的网络结构网络层网络层很简单,只有一个卷积层和一个全连接层,一个卷积层包括卷积、激活、下采样。我是用5
入门神经网络一样本采集在本科的时候对神经网络颇有兴趣,感觉很神秘,特别是当时的yolov5目标检测算法,让我感觉特别震撼,计算机在图像识别上已经超过了人眼。但是这么长时间以来一直停留在跑demo的阶段,没有静下心来学习,为此我计划搭建一个属于自己的神经网络作为入门标志,这是第一章,主要讲了说明采集样本的过程。建立一个怎样的网络我计划建立的网络结构,输入参数为陀螺仪三轴传感器的数据,输出内容为可能进
最近项目上需要混音算法,上网查阅了四种常用的混音算法,用python运行来做测试,测试完成的语音数据放在结尾可以下载混音算法一:加权平均这种方法很简单,直接将两个PCM样本相加,为了防止溢出再除以二,但是这种方式会导致声音细节丢失声音会变小,并且混入通道数越多,声音衰减越严重,毕竟原始音频直接右移了八位,实际测试下来也是如此,实现方法为:for i in range(0,sample_nums):
Makefile简单实用最近公司项目可能涉及到Makefile,今天来浅学一下!1、GCC使用当我们只有一个C文件时,可以用gcc编译直接生成文件,例如写一个main.c#include <stdio.h> int main() { printf("this is main.c\r\n"); return 0; }我们在命令行输入sudo gcc -c main.c
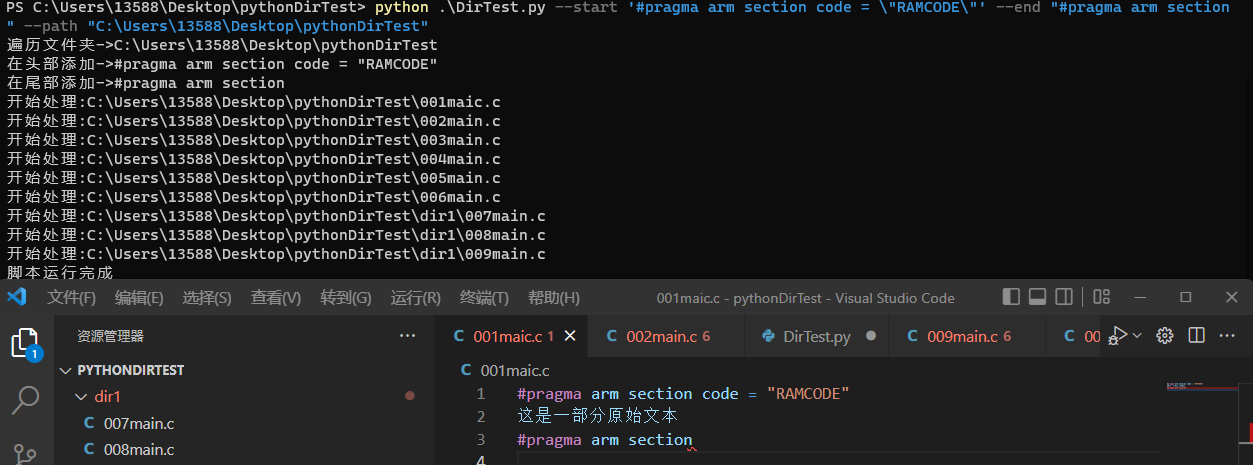
最近有一个需求,需要将一部分C代码文件在RAM中运行,每个运行在RAM中的代码需要在文件头部和尾部添加宏定义,但是遇到文件数量特别多的时候,手动添加很费劲,为此写了一个脚本实现批处理文件,在.c文件头部和尾部添加宏定义关于ROM和RAM运行速度的区别,可以查看这个博客:(点击我)脚本首先要实现参数传入,设置路径、在文件头部添加文本、文件尾部添加文本然后遍历所有文件夹,修改.c文件脚本源码:impo
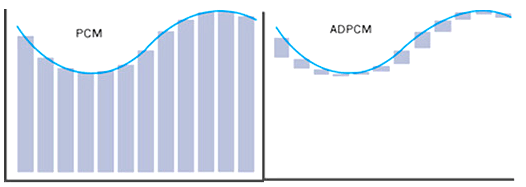
ADPCM是一种很简单实现的音频编码方式,真正的PCM相当占用内存,这对网络和内存的压力是相当大的,因此通常需要压缩编码,ADPCM是一种可以运行在单片机上的编码方式,原理如下:由于声音信号具有波形上的连续性,因此相邻两个采样值大小也非常接近,记录单个采样值通常需要 16bit,而记录前后两个采样点的差值(差分法),往往只需要 4bit,这便是 ADPCM 压缩编码的基本原理,因此通过 ADPCM

ESP32-CAM上传图像数据到Python上位机预防踩坑放在前面:目前安信可官方版的CAM模块已经停售,库存货比较贵,市面上的都是仿制的,质量良莠不齐,给开发带来了很多困扰,经过实际测试,发现山寨货主要有以下几个坑:1、发热严重,不加散热片长时间运行几乎到了烫手的地步,加上散热片也不会好很多2、在分辨率大于640*480后,信号变得异常的差,丢包严重,但如果用手捏着天线,数据传输又会稳定很多第二
使用MQTT做一个公网对讲机上一篇博客中,使用ESP32与ESP-NOW协议做了一个短距离对讲机(链接),发布了一个视频在B站评论区中,很多B友希望可以实现无限距离对讲,这样的话需要服务器转发,刚开始我想使用python写一个TCP或者UDP的转发功能,但是考虑到很多小白没有公网服务器,并且也不会使用python,于是我想到了互联网中的MQTT协议,MQTT协议天生为转发而生;MQTT协议是TCP
工作中需要使用到OPUS压缩音频,OPUS是一个开源音频编码方案,多种芯片支持OPUS编码,WINDOWS10上也自动支持,这是他的一些特性比特率从 6 kb/s 到 510 kb/s 采样率从 8 kHz(窄带)到 48 kHz(全频) 音频每帧时长从 2.5 ms 到 60 ms 同时支持恒定比特率 (CBR) 和可变比特率 (VBR) 从窄带到全频段的音频带宽 支持语音和